Inside Google’s Ironwood TPU — and what it teaches us about solving hard problems from first principles.
A Little Context: Why Interconnects Matter
Modern AI models — the kind that power image generation, language understanding, and scientific simulation — are far too large to run on a single chip. Training or running one of these models requires hundreds or thousands of processors working in tight coordination, passing data back and forth constantly. The network connecting those processors isn’t a background detail. It’s often what determines how fast and efficiently the whole system runs.
Google’s Ironwood is their seventh-generation Tensor Processing Unit (TPU) — a custom chip designed specifically for AI workloads. A single Ironwood ‘superpod’ links 9,216 of these chips together across 144 equipment racks, sharing 1.77 petabytes of memory. At that scale, the interconnect isn’t just plumbing. It’s one of the most consequential engineering decisions in the whole system.
The Problem Wasn’t Just “Connect the Chips”
Here’s what makes this interesting: the core challenge wasn’t simply getting 9,216 chips to talk to each other. That part, done crudely, isn’t impossible. The harder problem was that different AI tasks demand fundamentally different communication patterns — and those patterns need to change in real time.
Training a large model requires all chips to communicate with all other chips simultaneously — massive, distributed data exchange across the entire pod. Running a trained model (inference) looks completely different: fast, low-latency point-to-point communication between smaller groups of chips. A research experiment might need yet another configuration entirely.
The real requirement wasn’t a faster fixed network. It was a network that could become a different network — on demand, in microseconds, without rewiring a single cable.
In a conventional data center, network topology is defined by physical cables and electrical switches. Changing it means physically reconfiguring hardware — expensive, slow, and operationally disruptive. At the scale and pace that Google operates, that model simply doesn’t work.
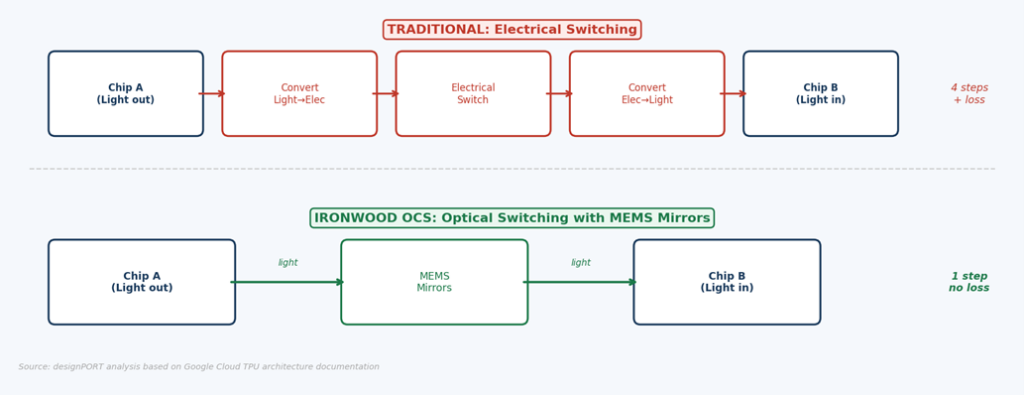
The Solution: Route Light, Not Electrons
Google’s answer is called Optical Circuit Switching (OCS). Instead of routing electrical signals through silicon switches, data travels as pulses of light — and the routing is done by physically tilting microscopic mirrors to redirect the light beams themselves.
The mirrors are MEMS devices: Micro-Electro-Mechanical Systems. These are machines measured in micrometers, fabricated on silicon wafers using the same photolithography techniques that make computer chips. They’ve been maturing quietly for decades in applications like smartphone accelerometers, automotive sensors, and medical pressure transducers. Google’s insight was recognizing that MEMS manufacturing had become reliable enough to deploy at a scale no one had attempted before.
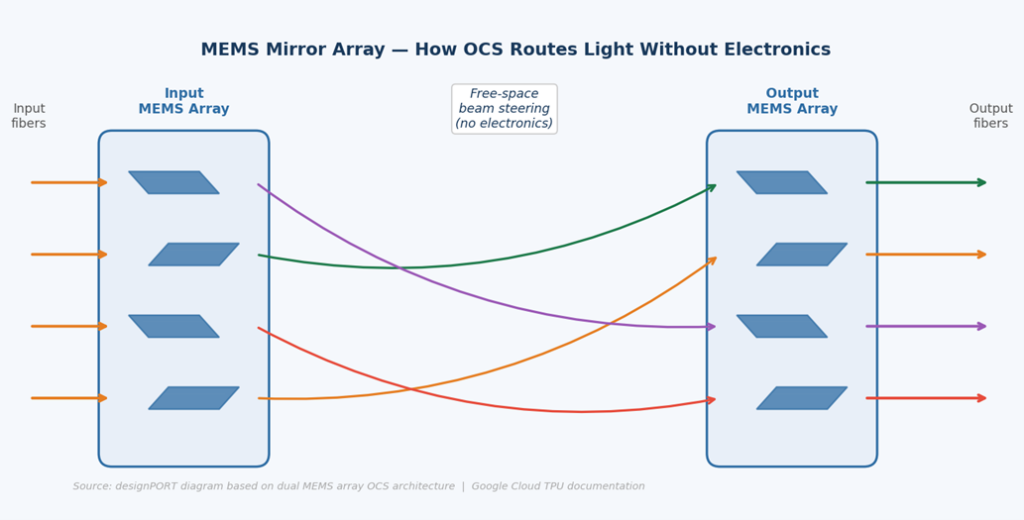
Each OCS unit uses two arrays of MEMS mirrors working together to steer beams in three dimensions. A dichroic mirror layer simultaneously transmits data-carrying light at one wavelength while reflecting a monitoring signal at another — giving the control system real-time visibility into every connection without interrupting data flow. Forty-eight of these units interconnect the full 9,216-chip superpod through 13,824 optical links.
Three Payoffs — One Expected, Two Surprising
Speed and efficiency were the goal. OCS delivers: the full pod runs at 9.6 Tb/s, and the entire optical interconnect accounts for less than 5% of system cost and power — a fraction of what equivalent electrical switching infrastructure would require.
Reconfigurability is the real differentiator. Because topology is defined by mirror angles rather than cables, the same physical hardware presents a completely different logical network to each workload. The pod can be dynamically sliced into cube, cigar, or rectangular configurations — each optimized for a different class of AI task — in microseconds, entirely in software.

Fault recovery turns out to be a third major benefit. When a chip or rack fails in a conventional network, restoring connectivity may require physical intervention. With OCS, the fabric manager reroutes around failures by adjusting mirror positions — recovering a full working topology in microseconds. Google reports roughly 50× less unplanned downtime compared to conventional interconnect architectures.
The Engineering Lesson
Google didn’t make electrical switches faster. They asked what a switch is actually for — redirecting a signal — and stripped away the assumption that the signal needed to become electricity to be redirected. Remove that one assumption, and a technology that’s been quietly maturing for decades turns out to be the right answer.
When optimization hits diminishing returns, the constraint you’re working around may not be a constraint at all — it may just be an assumption nobody thought to question.
At designPORT, this kind of cross-domain technology transfer is something we look for constantly. The most interesting solutions we develop — across medical devices, industrial automation, consumer products, and defense systems — frequently come from recognizing that a technique mature in one field is exactly what’s needed in another. The question isn’t always “how do we solve this?” Sometimes it’s “where has this already been solved?”
If your development program is running into a wall, challenge us.